Quote:
Originally Posted by Shohreh

Because FineReader did not carry formatting,
|
What did you export as?
You should see italics/bold showing up in the right half of Finereader:
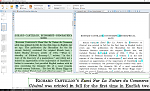
Left should display the original document, and the Right half should show all the actual OCRed text.
Did you select
Document Layout: "Formatted Text". In the dropdown, you can also select DOCX:

(Personally, I keep everything on "Exact Copy" until I'm ready to export the document. This makes the Left/Right halves match much more closely, making it easier to make corrections.)
Quote:
Originally Posted by Shohreh
I wanted to try other tools, especially since the PDF contained two layers, so it made sense to extract the "text" layer and see how it compared with running the PDF through FineReader.
|
I'm going to let you know right now, almost always the text layer is a garbled mess.
It's almost always better to re-OCR and work from scratch (see the PDF+OCR topics I previously linked to).
Quote:
Originally Posted by Shohreh
Re-add formatting (bold, italics, etc.)
|
Yes, exactly, which is why you want the computer doing that.
Finereader does a better job than any other tool at carrying over this (along with superscript/subscript/tables, etc. etc.).
Quote:
Originally Posted by Shohreh
Some hyphenated words weren't corrected by FineReader (but much better than starting from raw text from pdttotext, since FineReader uses a dictionary to fix most of those)
|
Yes, the soft/hard hyphen is a problem for anything, but again, Finereader seems to handle these the best.
Still a lot of manual correction needs to be done though, and that's where you use some of the tricks I listed in Post #15.
Spellcheck Lists are a fantastic way to catch/correct these things, along with Regex.
Quote:
Originally Posted by Shohreh
Re-add footnotes
|
Yep, that one's a pain, but there are methods.
Quote:
Originally Posted by Shohreh
Takes pictures of tables and… pictures, and insert them
|
Finereader should detect all that, and if not, you adjust the recognition boxes.
I explained some of this back in
2014: Post #5 in "Problems converting K2PDF Opt files to EPUB".
Quote:
Originally Posted by Shohreh
Build a ToC
|
As long as your headings are marked fine (<h1> <h2> <h3> ...), you regenerate that from Sigil.