Quote:
Originally Posted by Steven630

Thank you, lrui. I did try to make a recipe by imitating that of AdventureGamers before starting the thread, but it didn't work. And your recipe failed as well. I think this is because:
a. Since find... only finds the first object and stops, it will only find the "original link", not the link of next page. (That's the result of the fact that "previous page" button even exists on the first page, an anomaly that other websites don't have.)
b. The fact that "next page" button appears even on the last page would mean that a "nexturl" would always be found. (The recipe assumes that the "next page" button would not appear on the last page, or is unclikable. But the here there's no way to tell Calibre that it has already fetched all pages, and it would just go in loops, fetching the last page all the time).
In order to get around "a" and "b". I've tried something like this:
Code:
def append_page(self, soup, appendtag, position):
pager = soup.find('a', attrs={'class':'a1'})
if pager:
pt = pager.findNextSibling('a')
nexturl = pt['href']
soup2 = self.index_to_soup(nexturl)
texttag = soup2.find('div', attrs={'class':'content_left_5'})
newpos = len(texttag.contents)
self.append_page(soup2,texttag,newpos)
texttag.extract()
appendtag.insert(position,texttag)
def preprocess_html(self, soup):
self.append_page(soup, soup.body, 3)
pager = soup.find('div', attrs={'class':'text-c'})
if pager:
pager.extract()
return self.adeify_images(soup)
Anyway, this method would in theory at least fetch the second page. But while trying it out, I found no sign whatsoever of it making a difference. The log, the downloaded file—all seems extactly the same as if the code were not applied at all.
Which makes me wonder whether the recipe is applicable in the first place. The recipe of AdventureGamers is based on rss, while my recipe is based on index-parsing. This may explain the failure of the method.
All previous discussions on multi-page fetching appears to mention AdventureGamers recipe somehow. But nobody seemed to have succeeded. Given the unusualness of the specific article I'm trying to fetch, I don't think the method is going to work even it works on other websites. |
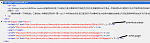
as you can see blow the pictres,there are two class="a1",but the AdventureGamers only has one class="nextpage"
so there is some issue with your code and mine. i think you can use match_regexps to match the next page link and set recursions to some number.
#Only one of BasicNewsRecipe.match_regexps or BasicNewsRecipe.filter_regexps should be defined.
match_regexps = [r'&page=[0-9]+']
Code:
original-link&page=4
original-link&page=3
original-link&page=2
original-link&page=1
#You should set recursions = 1. recursion= n means that links are followed upto depth n
recursions = 1
http://manual.calibre-ebook.com/news....match_regexps